I want to write about rating systems. This is something I feel very strongly about and have a good knowledge of. I have a degree in mathematics with statistics, but also I have practical experience actually introducting and helping implement a rating system into an independent RTS game. Their initial system had an issue with rating inflation and I helped them migrate to an Elo based system.
We need to understand why we want a rating system, and what such a system is for. In my mind a rating system should provide two key things. It should provide an assessment of relative strength and weaknesses of players. It should get more accurate as the number of games increases.
This really is all there is to it. If a system has these two properties then I would be happy to call it a rating system. There are however good and bad rating systems. Good rating systems take less mixing time to show relative strengths, they show less bias. Good rating systems also motivate players to play, although good rating systems do this naturally as a side effect of their accuracy rather than artificially through decay or other mechanisms. Why do we need a rating system at all? Well for team 5v5s I would actually take the drastic step of removing the rating system completely. I would replace 5v5 rating with a true Ladder System.
The Wikipedia article on Ladders is terrible, but basically it is a system where all teams are ordered, then you advance up the ladder by issuing a challenge to a higher team. If they refuse or they lose, then the teams swap places in the ladder. If they win then there is no change. Usually there is a limit of how far up the ladder you can challenge, typically 3-5 places.
For team 5v5s where the pool is smaller, and certainly for challenger 5v5, then this would make a lot of sense. This would see the best teams quickly rise to the top, and it puts a lot of pressure on those at the top to play to hold on to their spots. Usually these systems do incorporate a "pass" system, where you get say, 1 free "pass" for every 5 games played, so you don't always have to play every time challenged.
But for solo-queue this is not appropriate, nor perhaps is it suitable for lower level team 5s where the pool is much larger. In these instances a rating system is required. A rating system is a number that is a proxy for skill. It isn't your skill, it isn't even an estimate of skill, it is a number that has desirable behaviours that makes it act similar to how an estimate of skill would behave. Given a rating system we can observe some sanity checks.
Let us imagine we have a pool of 20 unknown players, and they all play each other twice. In such a system, we would expect two teams who drew with each other and had equivalent results against every other team to have the same rating. We would expect that if we took all the results as they happened, and played the "results stream" backward, then by the end with all the same results happening (but played backwards) then everyone would end up with the same ratings.
Many ratings systems do not have this property. Elo is a famous example. In the Elo system, if you play a relative unknown player and they later go on to have a rating of 2800, but you played them when they had 1700 rating, then their future success isn't taken into account in your rating. The reason for this historically is a lack of computing power. The elo system is simple to calculate, and can be done for a player by hand. A player's change in rating depends only on each players' ratings at the time of playing. But doesn't it make sense that if your opponent turns out to be Magnus Carlsen or Enrique Martínez that you get some recognition for that fact later?
Certainly it would allow for a much more accurate system. The mixing times would be dramatically reduced. This would come at the cost of computation power, as each rating would become linked to every other rating. Each time anyone plays, everyone's rating would change. People find it psychologically difficult to deal with the idea that their rating might change based on the outcome of a game that did not directly involve them. If they gained points they would be happy but if they lost points because of the outcome of another game they would feel crushed and helpless. They would feel like they don't directly influence their rating, and they would feel punished for past mistakes. This is why in many ratings systems, the past is discarded even when new information might help refine ratings. People don't want accurate ratings systems at the cost of mutability of their rating outside of their own results.
Another behaviour that ratings systems can have is predictability. If a chess master plays a senior master, then both sides can know before the game is done what will happen to their ratings in the event of a win, draw, or loss. They can each look at the payoffs and compare that against how likely they consider a victory. Lastly, a desirable behaviour of a rating system is that it can work as accurately for long distances as short distances. If a rating system is great at predicting that a 1650 rated player is approximately as good as at 1640 rated player then it has a use, but a good rating system lets a 2800 rated player play against a 1800 rated player. The matchmaking can match "one sided" events because the relative payoffs to rating matches the low chance of success for the weaker player.
In Elo ratings are only measured by distance. 2800 elo doesn't have any more meaning than 28000 elo, as the average elo is chosen arbitrarily when the system is set up. If the average is chosen to be 2000, then 2800 is 800 points above average. If the average point was chosen to be 27200, then the 2800 rated player would just instead have a rating of 28000. Note that it is scale invariant, it doesn't matter than one is 10x the size of the other, the only thing that matters in Elo is the difference between the ratings, which is additive not multiplicative.
Elo ratings can even be negative, it is quite possible to choose 0 as the average rating. Players better than average have a positive rating, players worse than average have a negative rating. This does not mess up the maths around the rating system. This is usually not done simply because people psychologically do not like to have a negative number. Typically 1000, 1200, 1500 are chosen as averages. From the definition of the ELo system:
A player whose rating is 100 points greater than his or her opponent's is expected to score 64%; if the difference is 200 points, then the expected score for the stronger player is 76%
You might wonder what "Expected Score" is. Well if you score 1 point for a win and 0 points for a loss, then "expected score" is simply your probability of winning. If draws are considered then a draw simply counts as 0.5 points, and then the equation is Pr(win) + 0.5 * Pr(draw) for your expected score. Note that Pr(win) + Pr(draw) + Pr(loss) = 1, since these are probabilities assigned to discrete (?) events.
In fact we can see the full table of expected score for rating differences here. The first column is how much higher your rating is than your opponent. The second column is your "expected score"
. | Rating above opponent | Chance of Victory | Rating improvement (win) | Rating decrement (loss) |
. | 800 | 99.01% | 0.32 | -31.68 |
. | 750 | 98.68% | 0.42 | -31.58 |
. | 700 | 98.25% | 0.56 | -31.44 |
. | 650 | 97.68% | 0.74 | -31.26 |
. | 600 | 96.93% | 0.98 | -31.02 |
. | 550 | 95.95% | 1.29 | -30.71 |
. | 500 | 94.68% | 1.70 | -30.30 |
. | 450 | 93.02% | 2.23 | -29.77 |
. | 400 | 90.91% | 2.91 | -29.09 |
. | 350 | 88.23% | 3.77 | -28.23 |
. | 300 | 84.90% | 4.83 | -27.17 |
. | 250 | 80.83% | 6.13 | -25.87 |
. | 200 | 75.97% | 7.69 | -24.31 |
. | 150 | 70.34% | 9.49 | -22.51 |
. | 100 | 64.01% | 11.52 | -20.48 |
. | 50 | 57.15% | 13.71 | -18.29 |
. | 0 | 50.00% | 16.00 | -16.00 |
. | -50 | 42.85% | 18.29 | -13.71 |
. | -100 | 35.99% | 20.48 | -11.52 |
. | -150 | 29.66% | 22.51 | -9.49 |
. | -200 | 24.03% | 24.31 | -7.69 |
. | -250 | 19.17% | 25.87 | -6.13 |
. | -300 | 15.10% | 27.17 | -4.83 |
. | -350 | 11.77% | 28.23 | -3.77 |
. | -400 | 9.09% | 29.09 | -2.91 |
. | -450 | 6.98% | 29.77 | -2.23 |
. | -500 | 5.32% | 30.30 | -1.70 |
. | -550 | 4.05% | 30.71 | -1.29 |
. | -600 | 3.07% | 31.02 | -0.98 |
. | -650 | 2.32% | 31.26 | -0.74 |
. | -700 | 1.75% | 31.44 | -0.56 |
. | -750 | 1.32% | 31.58 | -0.42 |
. | -800 | 0.99% | 31.68 | -0.32 |
Given this knowledge, everyone keeps playing until there are enough games to work out a graph of strengths. Let's say fnatic are 76% likely to beat Alliance, then they would be rated 400 points higher. If Alliance are 76% likely to beat TTD then they'd be rated 400 points higher, and so on and so forth all the way down to my Bronze 5 team. By the end there is a continuous set of results and estimates that lets us estimate the relative strengths of every team in LoL. This data is then used to rate the players such that the results observed are best described by the ratings given.
You could assign fnatic a rating of 200 points below the average. This would be a valid rating system, but it would make all of fnatic's results very, very unlikely. The rating system would suggest that the chance of fnatic having beaten gambit was microscopic, and indeed all their results would be deemed so unlikely, that if you took the probability of all the results having been as they were, it would be very small indeed. A rating is chosen so that the overall probability of all the results having been what they were, given the ratings ascribed, is maximised. Again, this isn't actually done precisely, since we want to avoid the "rewritten history" of ratings described earlier, but this is what the aim of the approximated version does.
Another thing, when I say "above average", the average (mean) elo is easy to calculate. It is exactly the starting elo. The reason for this is that elo has no rating inflation because for every point of Elo gained by a player, their opponent must lose an equal amount. We call this "zero-sum". The Zero sum property of rating systems is incredibly important as without that property ratings are not comparable from one day to the next.
Because precisely zero rating points are gained or lost by the system, we know the total amount of rating points in the system is Starting Elo*Number of players. To calculate the average rating we do (Total points in system) / (Number of players), but that is just (Starting Elo * Number of players) / (Number of players), which equals 1200.
The way that rating change in Elo is calculated is by picking a value (K value) which is a measure of how fast ratings can change. Long term this is actually also arbitrary, but typically 32 is chosen. This represents the maximum amount that a rating can change based on a single game. Some systems have importance attached to game modes by adjusting this value. a MTG site I used to play on had tournament games rated as 32 k value but self-arranged ladder matches had a 16 k value. This meant that tournaments affected your rating more.
However, while they do affect how fast the rating can move, they crucially don't affect the long term effects of the rating. As more and more games are played, the rating becomes closer to the "true skill" and eventually people win as many games as their rating expects them to, so how fast the rating moves does not matter because in theory the ratings don't much move. If the K value were too big, then because games can only have a single win/loss outcome, the ratings would be unstable. People would oscillate around their true rating. If the K value too large then this oscillation would make a mockery of the rating system itself. If they K value too small, then it would take too many games for people to get to their true rating. If someone's true rating is 800 points above average, then it already takes a minimum of 800/32 = 25 games to get there, assuming they were playing the highest level possible and winning every game. This is why rating is often hidden before 20 games is played, because early on the rating system has not reached accuracy.
That's a primer on the Elo system. The trade off between mixing time and long term stability is a difficult one, and many people aren't happy with the Elo system in its original form. So what can be done to improve it?
Well one improvement is the Glicko system. This is an Elo based system invented by Mark Glickman which introduces an extra term, a "ratings deviation" as a measure of how accurate a players rating is. The more a player plays, and the more consistent their results are with the rating system, the lower the RD. This means that as ratings settle, the swings in their rating get smaller. It also introduces "rating time periods" where instead of the rating updating each game, the ratings are periodically updated and all the results from that period are considered together. This introduces a step toward the "forward / backward" problem that I talked about earlier. With the Glicko system, it is the case that the games from within a rating time period can be played in any order. If a player does not play in a time period then instead of them losing rating (an artificiality that destroys the zero-sum property) they simply have their 'ratings deviation' increase, in other words their rating is marked as less accurate than previously thought.
The Glicko2 system goes even further and introduces a volatility measure. This is because a drawback of all the systems so far is that they assume that everyone has an underlying skill level and will eventually trend toward that. Adding a volatility measure helps when a player undergoes a step-change, for instance they get some tutoring. Now when they return stronger they will more quickly adjust to their new level. The full Glicko2 system is described on Mark Glickman's website at http://www.glicko.net/glicko/glicko2.pdf . The downside to this system is that there is a delay in updated ratings. If the time period was set at a week then a player who played Monday might not know their rating until the following Sunday. On the other hand this does introduce some excitement around the publication of the new weekly standings.
All the ratings systems so far have been about 1v1 rating systems. Extensions to team games are usually done in a number of ways. One way to do this is to pretend that each player played each opponent and scored a victory against each of them. In that case the K value is usually much reduced to compensate for the non-independence of the results (you either beat them all or lost to them all). Another method is to sum the ratings for each team and take the overall difference between the teams, and use that as the difference in the Elo system. This has the drawback of non-linearity though. A team of 1620 against a team of all 1600 would end up with a difference of 100. This would translate to the team of 1620 being 64% likely to win the game as estimated by the rating system. 1v1 a 1620 rated would be estimated to beat a 1600 rated 53% of the time. I guess the compounding of 5 players each 53% likely to win their lane would contribute to an overall dominance like that though, so the summation method wouldn't be inappropriate. The downside to this however is that everyone on a team would have their rating change by the same amount. For a non-absolute system such as Elo, this doesn't matter because an increase of 20 points to a rating of 800 means the same as an increase of 20 points to a 2800 rating, however there are some rating systems where that wouldn't be the case.
What would be most inappropriate for elo is to average the ratings. If a 1620 is 53% likely to beat a 1600, then a team of 5 1620 players are surely more than 53% likely to beat a team of all 1600 players, but this is a mistake I see ratings system implementers make. Other bad methods include taking the geometric mean: this is disastrous, ratings can be negative without special meaning!
Another method which I would like to explore but have not yet done the maths around is to define a win as 3 of 5 players in a team "winning" and looking at every combination of matchups across the 5v5 and looking overall the chance of having 3 or more of the 5 win as if it were 5 1v1s. Given this, that overall gives the "expected score" that Elo needs to recalculate the rating.
So far I have discussed some well developed rating sytems, but we can look at some bad rating systems to compare, to see what happens when rating systems are bad. One bad rating system would be the following: Start at zero points. Gain 1 point for a win, lose 1 point for a loss. Don't let points go negative, so losing at zero you stay on zero.
Now that sounds kind of OK, it's a fight to win. However, it has many, many terrible properties:
The advantage of such a bad system is that if we run simulations we can use the bad systems to have benchmarks against which to compare good systems. If a system starts to behave in any way similar to a bad system we can try to understand if there are undesirable properties of that system too.
Given all of the above, it is time to test the systems. Pictures are worth far more than words but before we get to the results I need to describe the set up.
I assume that "natural skill" is normally distributed among a population. I then populate 10,000 players with a random natural skill, sampling from the normal distribution with mean of 1000 and variance of 200. From these players I shall pick players uniformly at random and sample games against each other. The outcomes of the games will be based on their underlying skill.
I will see how close the fit is after 10, 20, 50, 100, etc games. Eventually the elo rating will reflect the true rating, in part because of how I'll be sampling the results. What will be interesting is to see how close the other rating systems get and their relative performance.
This isn't an ideal way to compare rating systems, as many of the assumptions made in setting up the simulation are the same assumptions made in the Elo system, so it is unfairly rewarded. For instance it is unlikely that skill is normally distributed.
If I had access to the full results for season 3 I would instead use those and compare the end rankings. This would for instance let us have real world examples of rankings which we could ourselves reflect on their accuracy. If I can license or otherwise access this data I will try to do this to produce season 3 full ratings lists across different systems. So that is the set up, I will simulate up to 10 million games across 10,000 accounts and look how accurately the rating systems match the underlying true skills.
Having run this simulation for 10,000 accounts and 1,000,000 random pairing of matches, the results for Elo look like this:
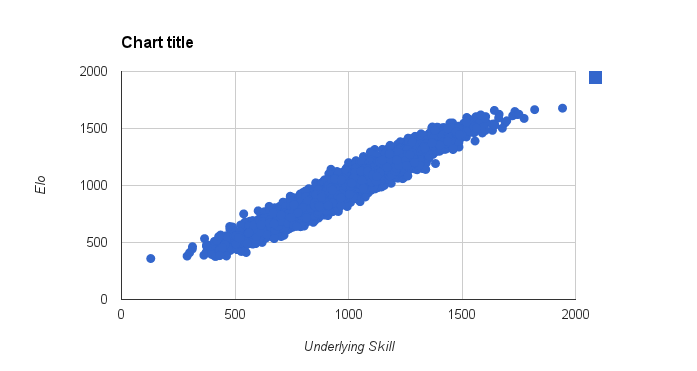
But this doesn't actually give us much insight, we always knew that Elo would be a good fit for a system modelled on Elo. The insight here comes from what happens if we drop to 100,000 games, just an average of 100 games per player.
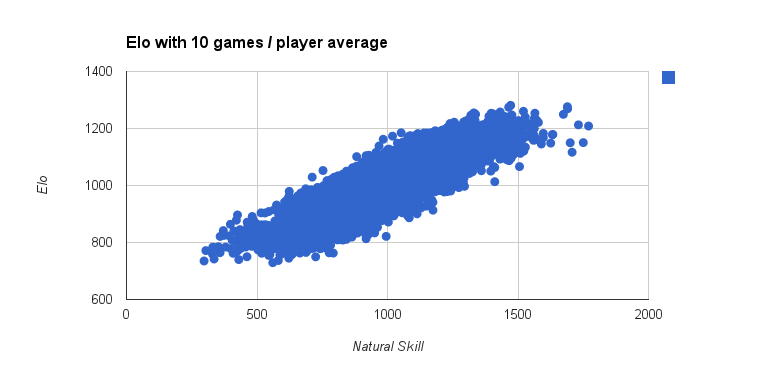
We can see the distribution is a lot "fatter", this represents more uncertaintly around a true skill. For someone Elo rated 1000 they might have true skill in a wider range. The range is still very wide even in the 100 games / player case though, with each elo spanning several hundred "true" skill. There is also a clear effect of the top and bottom not yet being high or low enough to account for true skill.
If we run 100,000,000 games, that is 10,000 per player, we should really see a might tighter distribution. Unfortunately at this point it starts to take a while to run the simulation, around 40 seconds, since I haven't used any concurrency.
The results are actually fairly similar, there is still a wide band. So even after 10,000 games per player, for any given rating there is a band 200+ wide that the players true skill could have been from.
This is an important conclusion. Even when the rating system perfectly describes the simulated model, the rating system can't say with a good accuracy what your true skill is, the accuracy is not more than 200 or so elo points, which equates to around a 10 game win or loss streak.
p.s. My code for running the simulation is below. There could well be bugs. It's written in go which means performance could be a lot higher if I used goroutines and channels. If I expand as I plan to, to being able to "slot in" different rating systems to compare then I will probably make such improvements.
One bug I've just noticed is that I didn't prevent players accidentally playing themselves. I'll fix that when I implement Glicko.
package main
import (
"fmt"
"math"
"math/rand"
"time"
)
func init() {
rand.Seed(time.Now().UTC().UnixNano())
}
func updateRatings(ratingWinner float64, ratingLoser float64) (float64, float64) {
//We assume A beat B
var Ea float64
Ea = 1 / (1 + math.Pow(10, ((ratingLoser-ratingWinner)/400)))
return ratingWinner + 32*(1-Ea), ratingLoser + 32*(Ea-1)
}
func match(SkillA float64, SkillB float64, ratingA float64, ratingB float64) (float64, float64) {
//Work out who wins
var Ea float64
Ea = 1 / (1 + math.Pow(10, ((SkillB-SkillA)/400)))
if rand.Float64() < Ea {
ratingA, ratingB = updateRatings(ratingA, ratingB)
} else {
ratingB, ratingA = updateRatings(ratingB, ratingA)
}
return ratingA, ratingB
}
func main() {
var players [10000]float64
var ratings [10000]float64
for key := range players {
players[key] = rand.NormFloat64()*200 + 1000
ratings[key] = 1000
}
for j := 0; j < 100000000; j++ {
a, b := rand.Intn(10000), rand.Intn(10000)
ratings[a], ratings[b] = match(players[a], players[b], ratings[a], ratings[b])
}
for key := range players {
fmt.Printf("%f,%f\n", players[key], ratings[key])
}
}